Table of Contents
AI video generation went from a research-lab demo to a working tool inside marketing, sales, education, and live event activations in less than three years. About 78% of B2B marketing teams now use AI-generated video in at least one campaign per quarter, and the underlying models keep getting better fast enough that the playbook from a year ago is already half-outdated.
What's harder to find is a clear-eyed read on how an AI video generator actually works under the hood, what the meaningful types are, and what the trade-offs look like in 2026. We've been building AI photo and video activations for over a decade, and we ship our own AI Video Booth on top of current generation models (Kling v3 as of April 2026), so we'll walk through the mechanics from a perspective that's lived in the product.
Key takeaways
- An AI video generator turns inputs (text, images, or both) into video by predicting motion frame-by-frame using diffusion models trained on huge video datasets.
- The category splits into four shapes: text-to-video, image-to-video, avatar-driven synthetic presenters, and live activations where guest input drives output.
- Marketing teams use AI video for product demos, short-form social, personalized email, ad creative, and event activations. Each has its own sweet spot.
- Output consistency varies more than AI image generation. Plan for creative variability, especially on motion and complex scene composition.
- Audio is mostly not there yet. Most outputs ship silent or with background music; speech-synced lip motion is improving but still frontier work.
What is an AI video generator, and how does it work?
An AI video generator is software that produces video content by combining one or more AI models, typically a diffusion model trained on video data, sometimes paired with a language model for prompt understanding. You feed it an input (a sentence, an image, an avatar selection, or some combination), and the system generates frames that move coherently from start to end.
The simplest mental model: where a traditional video pipeline films real footage and edits it together, an AI video generator predicts what each frame should look like based on patterns it learned from millions of training videos. Motion, lighting, camera angles, even physics-like behavior emerge from those patterns rather than being captured by a camera. That's why the output sometimes looks uncannily real and sometimes drifts into the dreamlike: the model is making informed guesses, not recording reality.
2026 is materially different from 2024 on three dimensions. Models are larger and better at temporal consistency (subjects don't morph mid-clip the way they did two years ago). Generation speed has compressed from minutes per second of output to near real-time on some flows. And the cost curve has bent sharply: median AI-assisted video production runs roughly $2,500 per finished minute now versus $4,200 for traditional production.
How does AI create videos?
Three steps power most current AI video generators, regardless of which vendor's stack you're using.
Step 1: input encoding. The generator takes your input (a text prompt, an image, an avatar, a reference video, or some combination) and converts it into a numerical representation the model can work with. Text gets tokenized and embedded; images get processed through a vision encoder; reference video gets sampled into representative frames.
Step 2: noise-to-video diffusion. The model starts with random noise and progressively refines it toward a coherent video sequence. At each refinement step, the model predicts what the noise should look slightly more like (closer to the desired output) given the input encoding. This is the same diffusion process that powers AI image generation, applied across the time dimension to produce motion.
Step 3: rendering and post-processing. The denoised output gets rendered as a video file with the right resolution, framerate, and codec. Some pipelines run a separate motion-smoothing pass, color correction, or upscaling. If the system supports it, audio (background music, voice synthesis, or sound effects) gets layered in here.
The clip you receive in your inbox or download from the platform is the result of a few seconds to a few minutes of model compute, depending on the complexity of the request and the model's optimization.

How are AI videos made: what's actually happening under the hood?
The technical answer most people want: how does the model know what motion looks like? Two ideas matter here.
First, training data scale. Modern AI video models train on millions of video clips paired with text descriptions. The model learns associations between language ("a person walking down a street at night") and visual patterns (motion vectors, lighting changes over time, perspective shifts). It's not hand-coded rules about how legs swing or shadows move; it's learned statistical patterns from observing real footage.
Second, the diffusion architecture itself. Diffusion models work by learning to reverse a noise process. During training, the model sees real videos progressively corrupted with noise and learns to predict what got corrupted. At generation time, it runs that process backward: starting from pure noise, it iteratively denoises toward what the prompt describes. Because it learned this process across many examples, it can generalize to new prompts at inference time.
This is also why AI video output varies even with identical prompts. The starting noise is different each run, and the denoising process has stochastic elements. Two generations from the same prompt can produce different motion paths, lighting, or scene composition. That variability is a feature when you're testing creative variants and a frustration when you're trying to ship a polished hero asset.
What are the different types of AI video generators?
The category is bigger than most people realize. Roughly four shapes, each solving a different problem.
Text-to-video. You write a prompt; the model generates a video clip from scratch. Tools like Synthesia, Runway, and OpenAI's Sora live here. Best for original creative concepts, ads, and explanatory content where you don't have source footage. The trade-off: less control over specific subjects (your CEO's actual face won't appear in a text-to-video output unless the model has seen them in training data).
Image-to-video. You provide an input image; the model generates a short clip animating that image. Kling, Runway's image-to-video flow, and our own AI Video Booth use this pattern. Best when you want a specific subject to stay consistent. The trade-off: motion variability is real, and complex multi-subject scenes still trip the models.
Avatar-driven synthetic video. You pick a pre-trained avatar (or train your own from a few minutes of source footage), write a script, and the system produces a video of that avatar speaking your script with synchronized lip motion. Synthesia and HeyGen own this lane. Best for sales outreach, training content, and corporate communications. The trade-off: the avatar always looks slightly synthetic; viewers can usually tell.
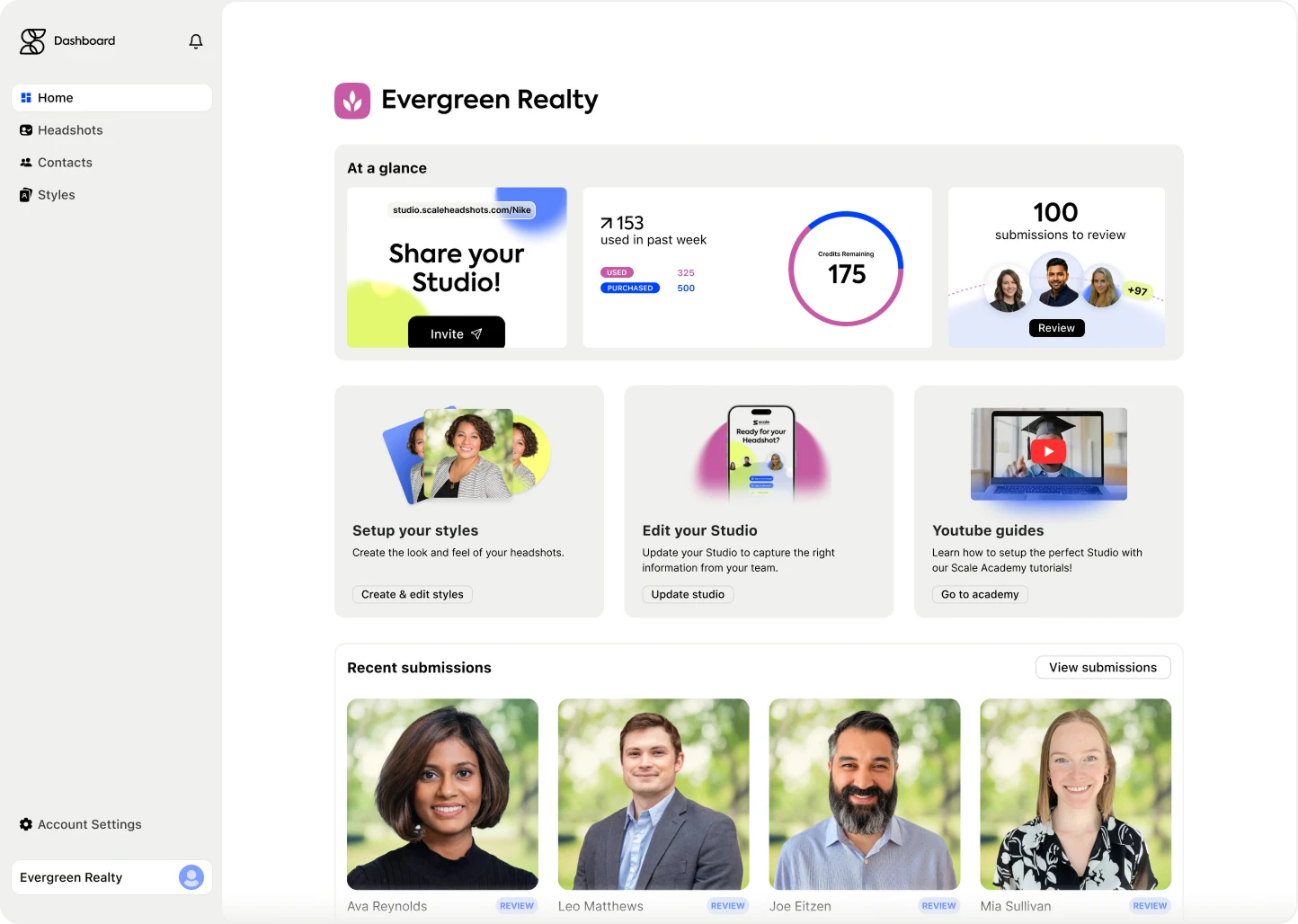
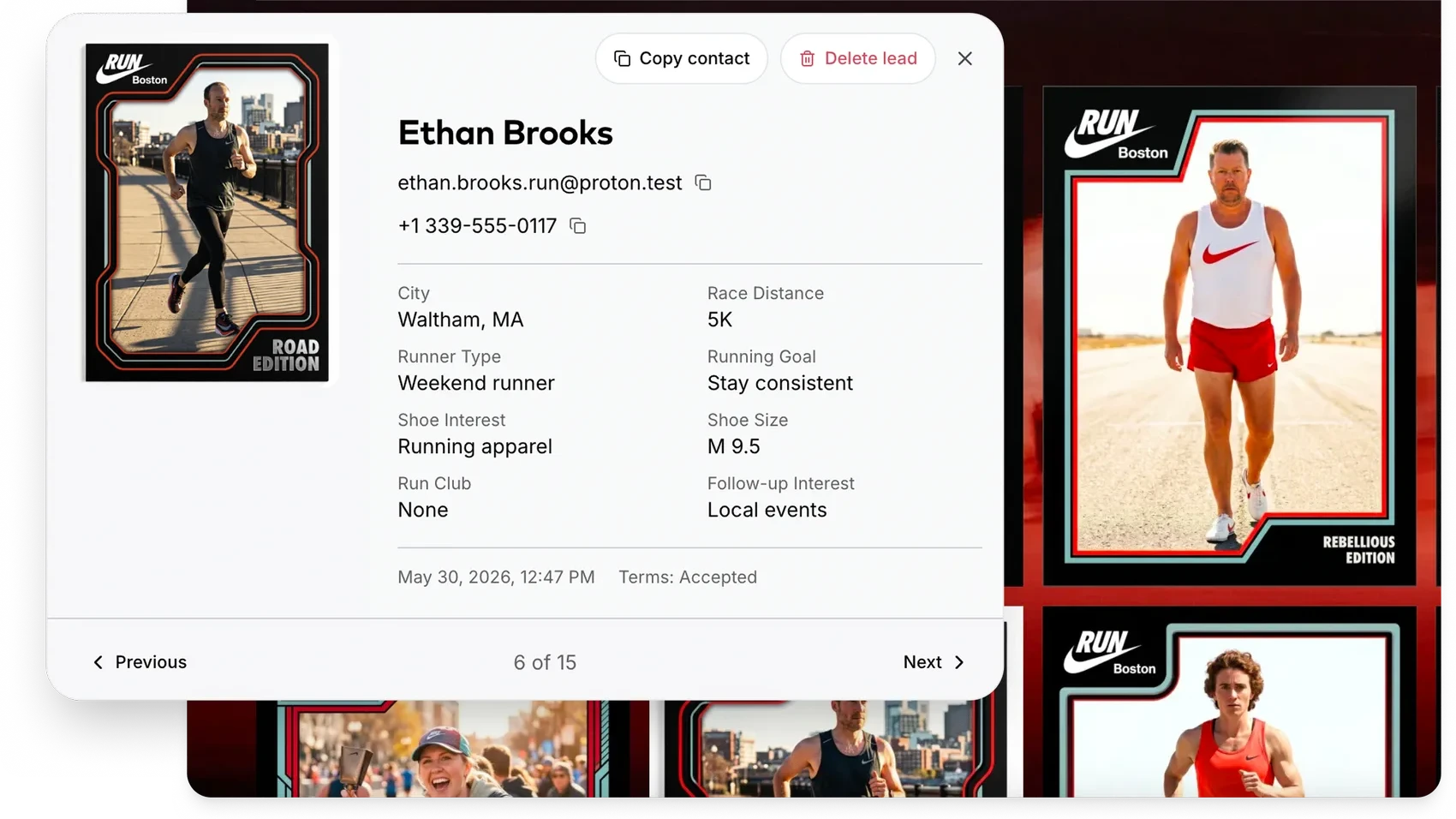
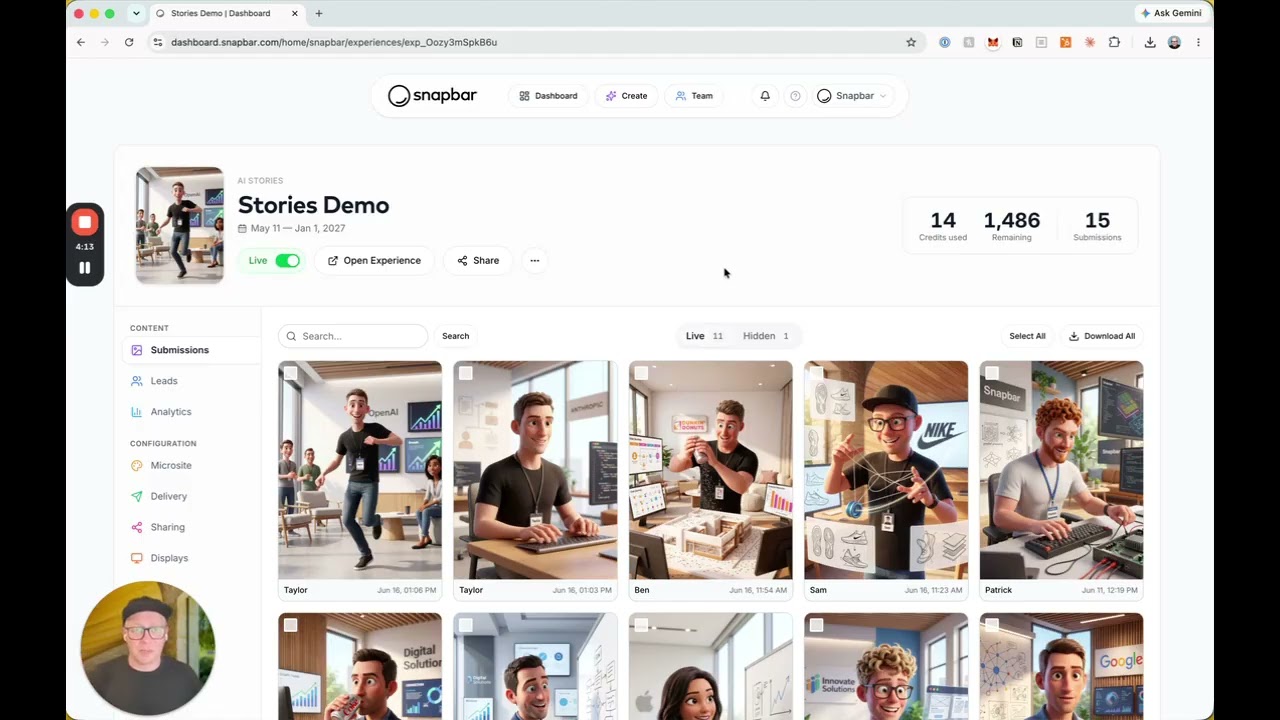
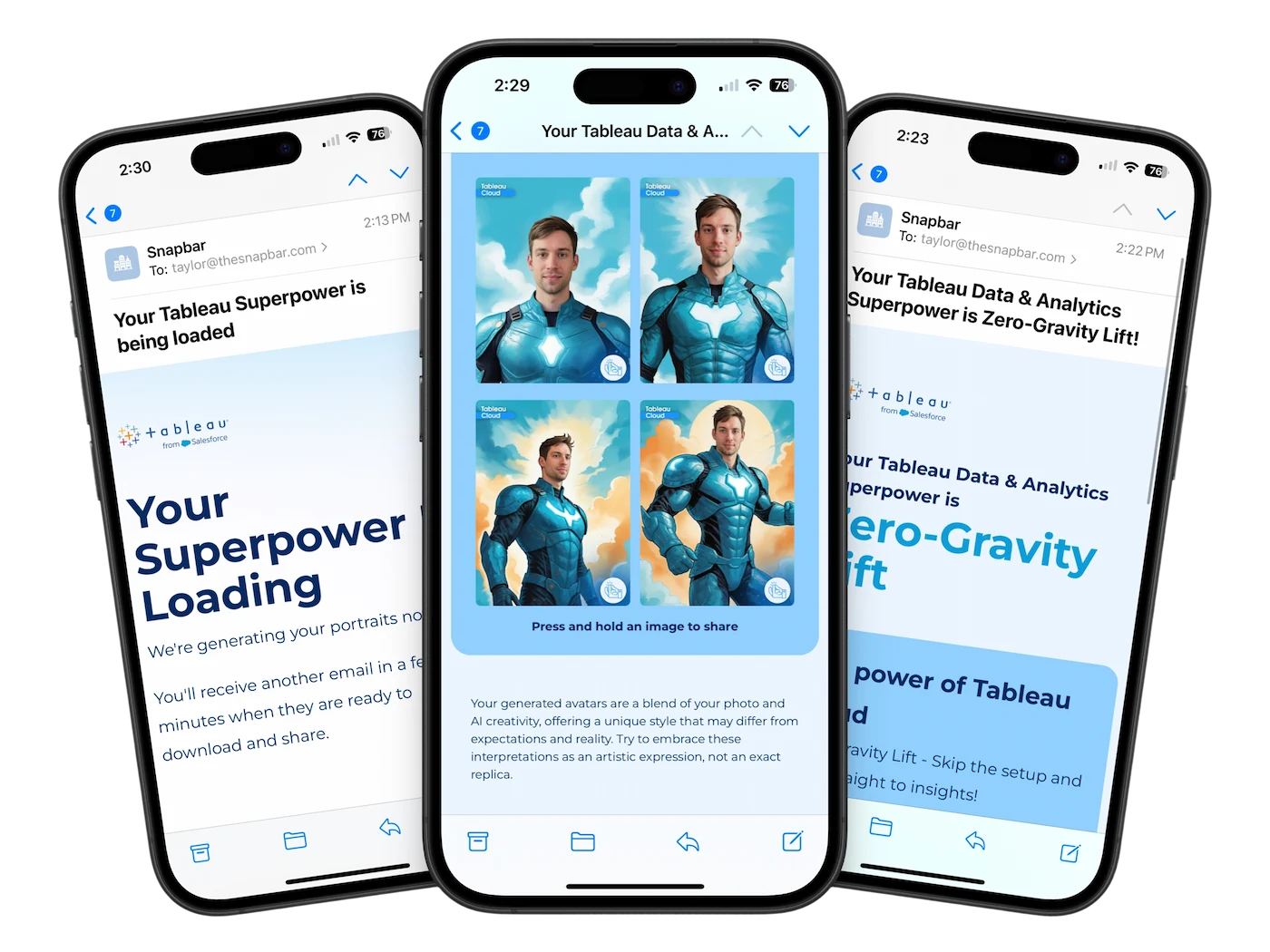
Live activations. This is the lane we live in. At a brand event or trade show, a guest captures a photo, the platform generates an AI portrait, and that portrait runs through an image-to-video model to produce a 4-second clip the guest can post anywhere. The marketer designs the experience; the audience is the operator. Best for engagement, lead capture, and earned social reach. The trade-off: each guest gets a unique output, which makes traditional brand-control workflows harder to apply.
How do you use an AI video generator effectively?
Three principles consistently separate teams getting real value from teams generating noise.
Match the tool to the use case. Don't try to make text-to-video do the work of image-to-video. Don't try to make a synthetic avatar carry a campaign that needs an actual face viewers know. The model categories above each have a sweet spot; pick the right one and you'll spend less time fighting the output.
Iterate fast, accept variability. AI video rewards teams who can ship five variants in the time it used to take to produce one polished asset. Use the speed to test, not to ship the same thing faster. Build review gates so brand and legal touch every variant before paid spend goes behind it, but don't insist on perfect first-try outputs that the technology can't reliably deliver yet.
Pre-tune the prompt and motion style during onboarding. Generic prompts produce generic outputs. The teams getting the most consistent results invest 30 to 60 minutes in prompt engineering for any sustained AI video program: defining the visual style, motion behavior, color palette, and composition guardrails up front.
How do brands use AI video generators in marketing?
Five mature use cases account for most of the value being captured today.
- Product demos and explainer content. About 31% of AI video output by volume. Synthetic presenters paired with screen capture, scaled across languages and product variants without re-shooting.
- Short-form social content. Roughly 67% of AI-generated video is under 60 seconds. The format rewards iteration speed, which AI video provides.
- Personalized email video. First-frame personalization (recipient's name on a sign, their company logo on a hoodie) drives roughly 4x the conversion rate of generic video email blocks.
- Ad creative variants. One concept, dozens of language and audience versions, generated and tested at near-zero marginal cost per variation.
- Live event activations. Guest captures a photo, platform generates an AI video clip, guest shares it. The brand gets lead capture and organic social reach. We've seen this pattern hit a 95% email open rate, well above typical post-event email benchmarks.
If you want a deeper read on how marketers are pairing these use cases together, our piece on the top uses for AI video in marketing walks through the campaign-level patterns and real brand examples.

What we've learned shipping AI video activations
The brands that get the most out of AI video generators aren't the ones with the biggest budgets. They're the ones who treat the output as a creative medium with its own grammar, not a cheaper shortcut to traditional video. The teams that try to force AI video into the shape of a polished broadcast asset usually end up frustrated. The teams that lean into the variability, ship more variants, and let the audience or algorithm pick winners come out ahead.
What's the future of AI video generation in 2026 and beyond?
Three frontiers are moving fast enough that the playbook in 2027 will look different again.
Audio is closing the gap. The biggest current limitation is that most AI video output ships silent or with background music. Speech-synced lip motion exists but isn't reliable across all subjects yet. The next 12 months should see synchronized audio become a default, which opens up entire categories (sales outreach personalization, full ad creative, training content) that today require separate audio production.
Multi-scene mini-movies. Current generators are best at 4-to-8-second clips. Multi-scene composition (two characters, three locations, a 30-second narrative arc) is technically possible but unreliable. As models extend their effective length and consistency, longer-form AI video becomes viable. That changes which use cases are economically achievable.
Better creative control. The most-cited frustration today is that the same prompt can produce wildly different outputs. Better seed control, more granular motion specification, and reference-frame conditioning are all in active development. When that lands, AI video shifts from "creative roulette" to "controllable production tool" and adoption accelerates again.
For now, the smart move is to use AI video generators where their current capabilities clearly fit (short-form, personalization, variant testing, live activations) and resist forcing them into roles where the technology isn't ready yet. The teams getting the most mileage are building workflows that tolerate creative variation and use the speed of generation as the lever, not the polish of any single output.